为什么需要微调?
在开始学习微调之前,大家首先还是要搞清楚为什么要微调?在什么情况下需要微调?
我们平常接触到的大模型如 GPT、DeepSeek 等都是基于海量的通用数据训练而成的,它们具备非常强大的语言理解和生成能力,能够处理多种自然语言任务。但是,这些模型在某些特定领域或任务上的表现可能并不理想,或者说还能够做到表现的更好。下面是需要微调的几个主要原因:
领域专业化:让模型掌握“行业黑话”
- 原因:通用模型的训练数据覆盖面广,但难以深入垂直领域的知识体系和专业术语。例如医学诊断需理解病理特征,法律咨询需熟悉法条逻辑。当模型在专业领域认知不够时,会出现比较严重的幻觉问题,也就是胡乱回答,微调可以很好的解决这个问题
- 典型场景:
- 医学问答:输入症状描述,模型需结合医学知识库输出可信的初步诊断建议。
- 法律咨询:分析“未成年人合同效力”时,需准确引用《民法典》相关条款。
任务适配:调整模型的“输出模式”
- 原因:不同任务对模型能力的要求差异显著——分类任务需结构化输出,生成任务需语言创造力。
- 典型场景:
- 文案生成:训练模型以幽默风格撰写广告文案(如“这杯咖啡,比老板的早安更提神”)。
- 心理咨询:从“情绪识别”转向“疏导对话”,需调整输出为引导性提问而非结论性判断。
能力纠偏:解决模型的“偏科问题”
- 原因:通用模型可能对某些任务过度敏感(如政治倾向)或表现不足(如冷门领域的长尾问题)。
- 典型场景:
- 民俗推理:输入生辰八字与手相特征时,模型需按传统命理逻辑生成连贯解释,而非套用通用话术。
- 边缘案例:处理“宠物能否继承遗产”时,需结合继承法细则而非泛泛回答。
安全与成本:
- 数据安全:当训练数据涉及隐私(如患者病历、企业内部文档)时,本地化微调可避免云端传输风险。
- 成本效率:相比从头训练(需百万级算力),微调仅需少量领域数据即可显著提升任务表现,适合中小规模企业。
微调的基本流程
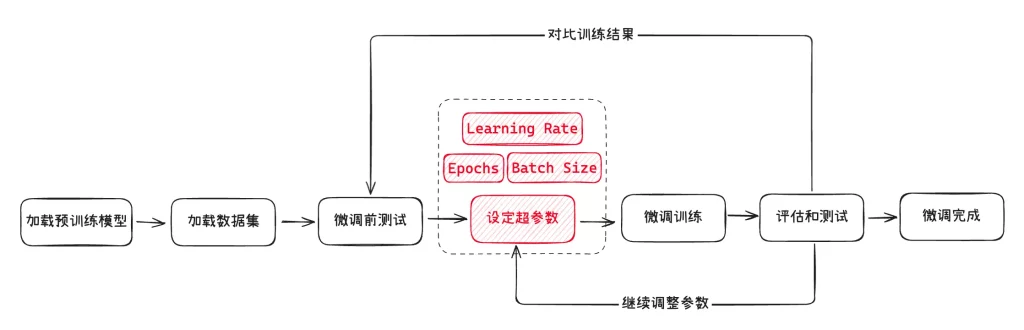
以下是一个常见的模型微调的过程:
- 选定一款用于微调的预训练模型,并加载
- 准备好用于模型微调的数据集,并加载
- 准备一些问题,对微调前的模型进行测试(用于后续对比)
- 设定模型微调需要的超参数
- 执行模型微调训练
- 还使用上面的问题,对微调后的模型进行测试,并对比效果
- 如果效果不满意,继续调整前面的数据集以及各种超参数,直到达到满意效果
- 得到微调好的模型
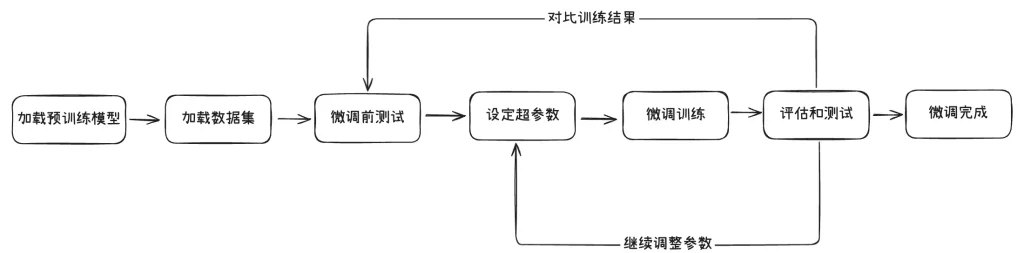
在这个流程里,有几个基本概念需要大家提前了解,微调模型的过程就像是给一个已经很聪明的学生“补课”,让他在某个特定领域变得更擅长。
概念1:预训练模型
预训练模型就是我们选择用来微调的基础模型,就像是一个已经受过基础教育的学生,具备了基本的阅读、写作和理解能力。这些模型(如 GPT、DeepSeek 等)已经在大量的通用数据上进行了训练,能够处理多种语言任务。选择一个合适的预训练模型是微调的第一步。
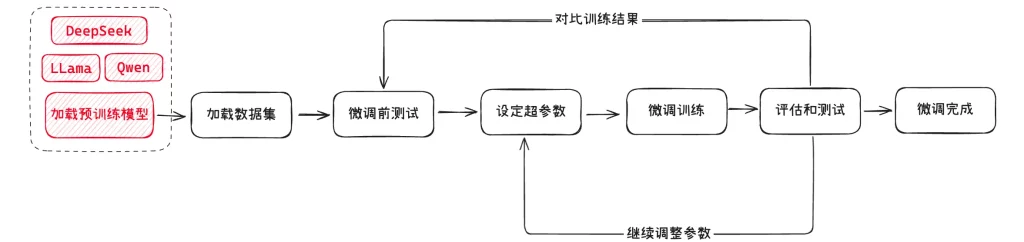
一般来说,为了成本和运行效率考虑,我们都会选择一些开源的小参数模型来进行微调,比如 Mate 的 llama、阿里的 qwen,以及最近爆火的 DeepSeek(蒸馏版)

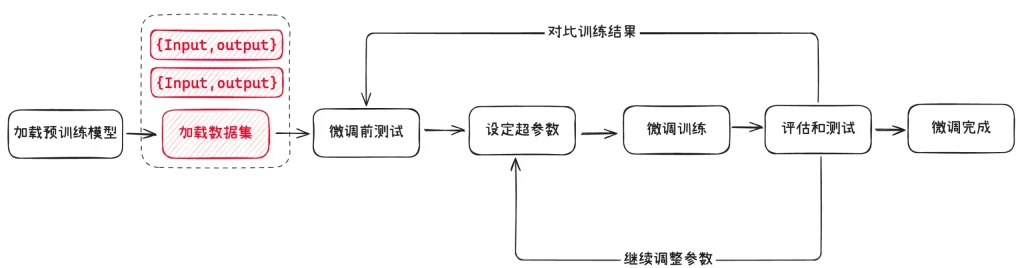
概念2:数据集
数据集就是我们用于模型微调的数据,就像是“补课”时用的教材,它包含了特定领域的知识和任务要求。这些数据需要经过标注和整理,以便模型能够学习到特定领域的模式和规律。比如,如果我们想让模型学会算命,就需要准备一些标注好的命理学知识作为数据集。
一般情况下,用于模型训练的数据集是没有对格式强要求的,比如常见的结构化数据格式:JSON、CSV、XML 都是支持的。
数据集中的数据格式也没有强要求,一般和我们日常与 AI 的对话类似,都会包括输入、输出,比如下面就是一个最简单的数据集:

为了模型的训练效果,有时候我们也会为数据集添加更丰富的上下文,比如在下面的数据集中,以消息(messages)进行组织,增加了 System(系统消息,类似于角色设定),user(用户消息)、assistant(助手回复消息)的定义,这样就可以支持存放多轮对话的数据,这也是 OPEN AI 官方推荐的数据集格式:

大家练习或测试的话可以去网上找一些公开数据集,这里推荐两个可以获取公开数据集的网站:
第一个:Hugging Face(🪜),我们可以把 Hugging Face 平台比作 AI 领域的 GitHub,它为开发者提供了一个集中化的平台,用于分享、获取和使用预训练模型和数据集。就像 GitHub 是代码共享和协作的中心一样,Hugging Face 是 AI 模型和数据共享的中心。在后面的实战环节中我们还会用到它:
如果你没有🪜,也可以退而求其次,选择国内的一些类似社区,比如 GitCode 的 AI 社区:
概念3:超参数
超参数就像是你在给模型 “补课” 之前制定的教学计划和策略。它们决定了你如何教学、教学的强度以及教学的方向。如果你选择的教学计划不合适(比如补课时间太短、讲解速度太快或复习策略不合理),可能会导致学生学习效果不好。同样,如果你选择的超参数不合适,模型的性能也可能不理想。
一些关键的超参数的含义,我们将在后面的实战中继续讲解。
初识:通过平台微调大模型
目前市面上很多 AI 相关平台都提供了在线微调模型的能力,比如我们以最近比较火的硅基流动为例:
我们进入硅基流动后台的第二项功能就是模型微调:

选择预训练模型
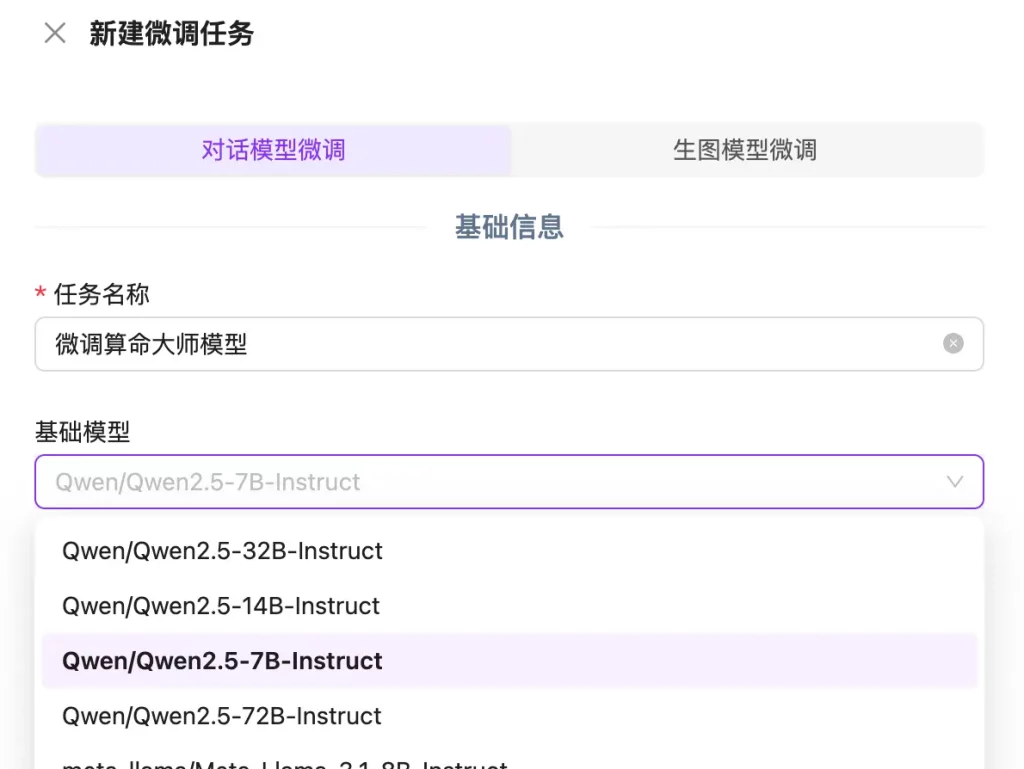
我们尝试新建一个微调任务,可以看到目前硅基流动支持微调的模型还不是很多,而且也没看到 DeepSeek 相关模型,这里我们选择 Qwen2.5-7B 来测试一下:
准备数据集
下一步就是选择数据集:
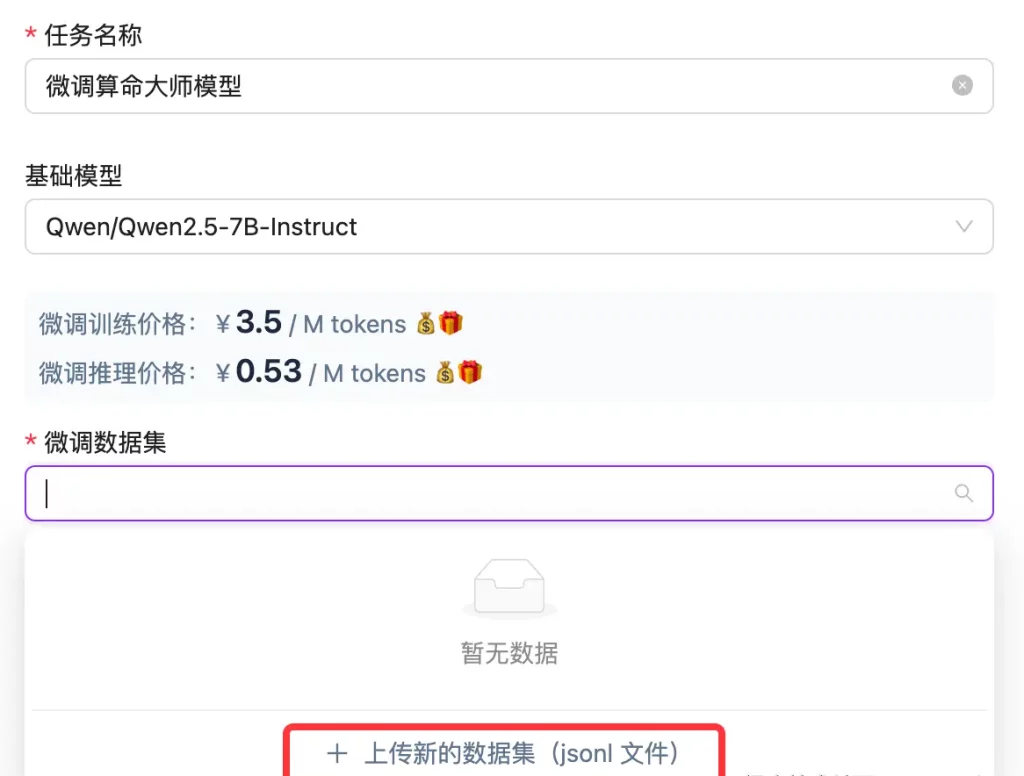
我们目前硅基流动仅支持 .jsonl 格式的数据集:
JSONL 文件(JSON Lines)是一种特殊的 JSON 格式,每一行是一个独立的 JSON 对象,JSONL 文件是“扁平化”的,彼此之间没有嵌套关系。

且需符合以下要求:

看着挺复杂的,其实和我们上面介绍的 OPEN AI 官方推荐的数据集格式要求是一样的:

对应 jsonl 的数据就是这样:

验证数据集
数据集上传完成后,下一步就是输入一个微调后模型的名字,以及设置验证数据集。
首先我们想要微调一个算命大师模型,那我们就以 fortunetelling 来命名:
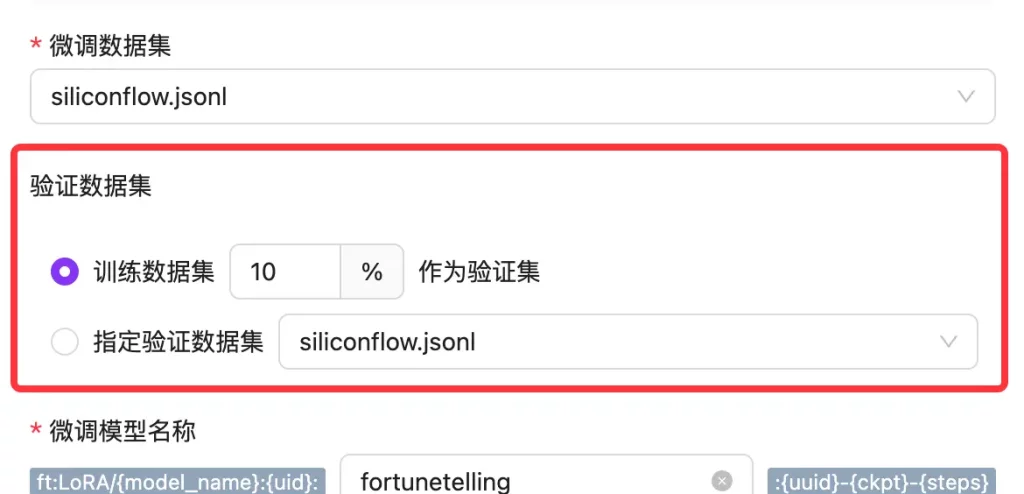
然后就是验证数据集:
验证数据集 就是从我们的整体数据中划分出来的一部分数据。它通常占总数据的一小部分(比如 10%~20%)。这部分数据在训练过程中不会被用来直接训练模型,而是用来评估模型在未见过的数据上的表现。
简单来说,验证数据集就像是一个“模拟考试”,用来检查模型是否真正学会了知识,而不是只是“背诵”了训练数据。
这里我们选择默认的 10% 即可。
超参数设置
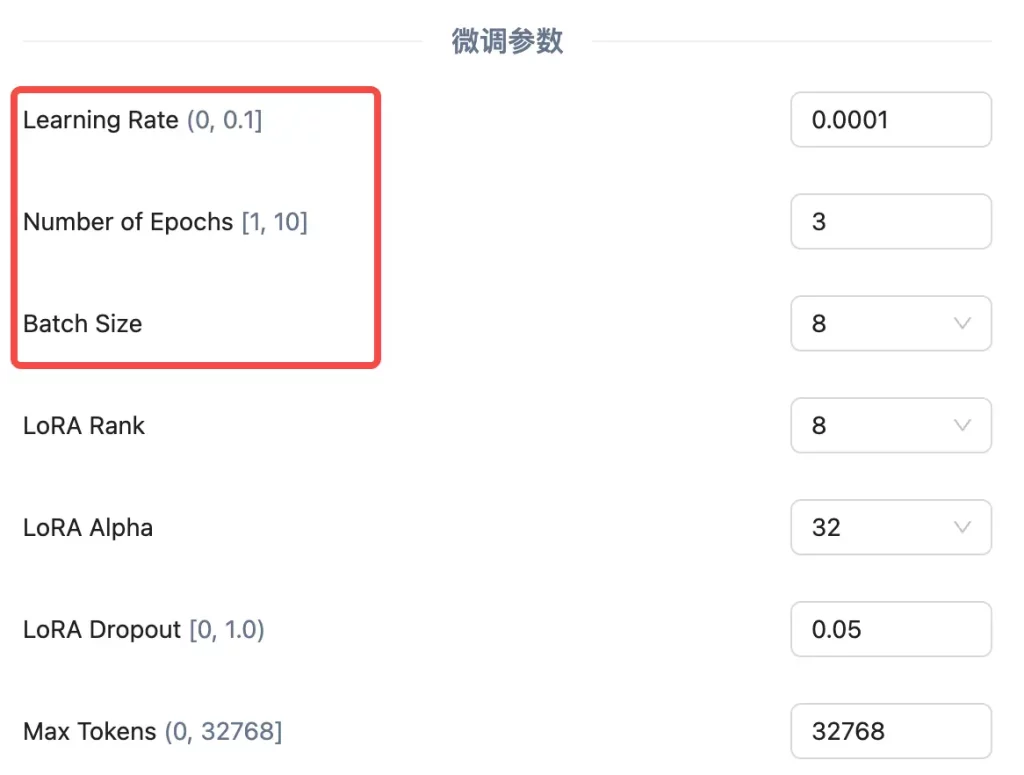
最后就是设置一些模型训练的 “超参数” 了,给出可以设置的参数非常多,我们这里只介绍最关键的三个参数:
为了方便理解,我们还以考试前复习的例子来进行讲解,假设你正在准备一场重要的考试,你有一本厚厚的复习资料书,里面有 1000 道题目。你需要通过复习这些题目来掌握考试内容。
训练轮数(Number of Epochs) Epoch 是机器学习中用于描述模型训练过程的一个术语,指的是模型完整地遍历一次整个训练数据集的次数。换句话说,一个 Epoch 表示模型已经看到了所有训练样本一次。
通俗来说,训练轮数就是我们从头到尾复习这本书的次数。
- 轮数少:比如你只复习一遍,可能对书里的内容还不是很熟悉,考试成绩可能不会太理想。
- 轮数多:比如你复习了 10 遍,对书里的内容就很熟悉了,但可能会出现一个问题——你对书里的内容背得很熟,但遇到新的、类似的问题就不会解答了,简单讲就是 “学傻了“,只记住这本书里的内容了,稍微变一变就不会了(过拟合)。
学习率(Learning Rate) 决定了模型在每次更新时参数调整的幅度,通常在 (0, 1) 之间。也就是告诉模型在训练过程中 “学习” 的速度有多快。学习率越大,模型每次调整的幅度就越大;学习率越小,调整的幅度就越小。
通俗来说,学习率可以用来控制复习的“深度”,确保不会因为调整幅度过大而走偏,也不会因为调整幅度过小而进步太慢。如果你每次复习完一道题后,你会根据答案和解析调整自己的理解和方法。
- 学习率大(比如0.1):每次做完一道题后,你会对解题方法进行很大的调整。比如,你可能会完全改变解题思路。优点是进步可能很快,因为你每次都在进行较大的调整。缺点就是可能会因为调整幅度过大而“走偏”,比如突然改变了一个已经掌握得很好的方法,导致之前学的东西都忘了。
- 学习率小(比如0.0001):每次做完一道题后,你只对解题方法进行非常细微的调整。比如,你发现某个步骤有点小错误,就只调整那个小错误。优点是非常稳定,不会因为一次错误而“走偏”,适合需要精细调整的场景。缺点就是进步会很慢,因为你每次只调整一点点。
批量大小(Batch Size) 是指在模型训练过程中,每次更新模型参数时所使用的样本数量。它是训练数据被分割成的小块,模型每次处理一个小块的数据来更新参数。

通俗来说,批量大小可以用来平衡复习速度和专注度,确保既能快速推进复习进度,又能专注细节。假设你决定每次复习时集中精力做一定数量的题目,而不是一次只做一道题。
- 批量大(比如100):每次复习时,你集中精力做100道题。优点是复习速度很快,因为你每次处理很多题目,能快速了解整体情况。缺点是可能会因为一次处理太多题目而感到压力过大,甚至错过一些细节。
- 批量小(比如1):每次复习时,你只做一道题,做完后再做下一道。优点是可以非常专注,能仔细分析每道题的细节,适合需要深入理解的场景。缺点就是复习速度很慢,因为每次只处理一道题。
在实际的微调场景中,我们需要通过一次次的调整这些参数,最后验证对比模型效果,来产出效果最好的微调模型。当然,如果你是小白用户,这些参数简单理解就行了,刚开始不需要调整这些参数,默认推荐的一般可以满足大部分场景的需求。
微调后调用
微调完成后,我们可以得到一个微调后模型的标识符:
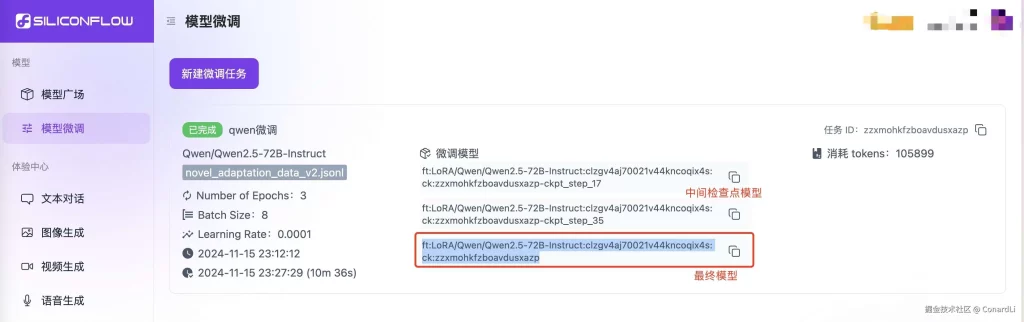
后续我们可以通过接口(/chat/completions)即可直接调用微调后的模型:
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
messages = [
{"role": "user", "content": "用当前语言解释微调模型流程"},
]
response = client.chat.completions.create(
model="您的微调模型名",
messages=messages,
stream=True,
max_tokens=4096
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
我们现在已经了解了模型微调需要的大部分基础概念,也通过硅基流动平台走完了一个完整的微调流程,但是在这个过程中我们发现有几个问题:
- 可以选择的基础模型太少了,没有我们想要的 DeepSeek 相关模型
- 模型训练过程中的 Token 消耗是要自己花钱的,对于有海量数据集的任务可能消耗比较大
- 微调任务触发不太可控,作者在测试的时候创建的微调任务,等了一天还没有被触发,当然这可能是硅基流动最近调用量太大,资源不足的问题,换成其他平台(比如 OPEN AI Platfrom)可能好一点,但是总归这个任务还是不太可控的。
为了解决这个问题,最终我们还是要使用代码来微调,这样我们就能灵活选择各种开源模型,无需担心训练过程中的 Token 损耗,灵活的控制微调任务了。
当然,看到这里,不会写代码的同学也不要放弃,因为前面大部分的概念我们已经了解过了,下面我会尽可能的让大家在不懂代码的情况下也能完整运行这个过程。