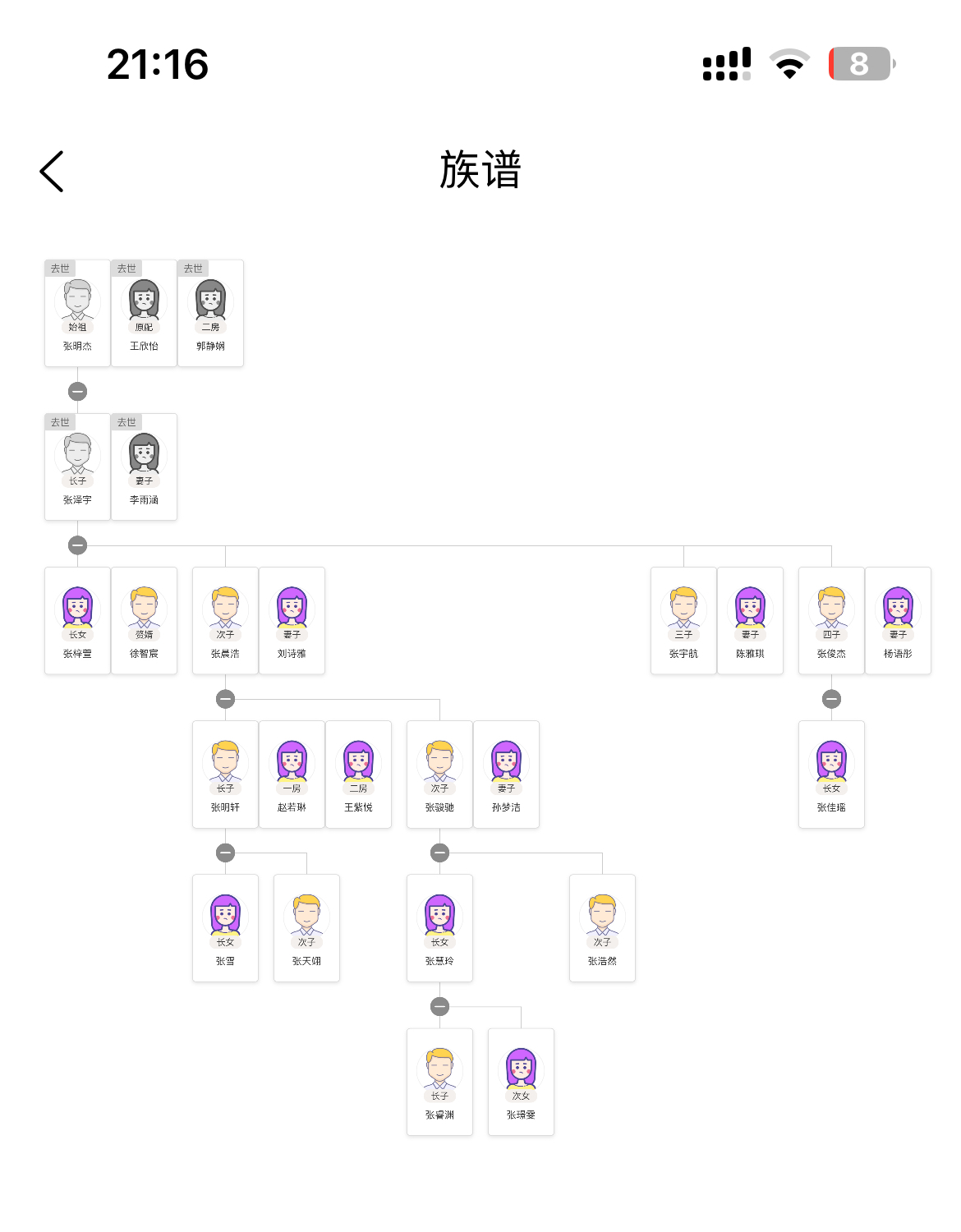
在数字化时代,记录和保存家族历史变得前所未有的简单。无论你是想追踪家族几代人的故事,还是仅仅想为后代留下一些记忆,一个好的数据库结构都能帮上大忙。今天,我们就来聊聊如何设计一个既简单又高效的族谱数据库,即使是技术小白也能轻松上手。
一、为什么要用数据库?
想象一下,你的家族已经有几百年的历史,你想知道某个祖先有多少个孩子,或者他们的孙子孙女都有谁。如果这些信息都写在纸上,查找起来可能会非常麻烦。但如果把这些信息存储在一个数据库里,只需要一条简单的查询命令,就能迅速得到答案。
二、我们的目标
我们需要设计一个数据库,可以:
- 记录每个家族成员的基本信息(名字、性别、出生日期等)。
- 显示家族成员之间的关系(父子、母子关系)。
- 轻松找到某个人的所有后代或祖先。
三、表结构设计
为了实现上述目标,我们创建了一个名为family_members的表格。这个表格有几个重要的列:
id: 每个家族成员的唯一编号。
name: 家族成员的名字。
gender: 性别,M代表男性,F代表女性。
birth_date: 出生日期。
father_id: 父亲的ID编号。
mother_id: 母亲的ID编号。
index_id: 用来记录从根节点到当前节点路径上的所有父节点ID,使用固定长度编码避免误匹配问题。
created_by_uid:创建者ID编号。
CREATE TABLE family_members (
id INT AUTO_INCREMENT PRIMARY KEY,-- 每个家族成员的唯一编号
name VARCHAR(255) NOT NULL, -- 家族成员的名字
gender ENUM('M', 'F') NOT NULL, -- 性别,M代表男性,F代表女性
birth_date DATE, -- 出生日期
father_id INT DEFAULT NULL, -- 父亲ID
mother_id INT DEFAULT NULL, -- 母亲ID
index_id VARCHAR(150), -- 路径编码
created_by_uid INT NOT NULL, -- 创建者的用户ID
INDEX idx_index_id (index_id), -- 为index_id创建索引以加快查询速度
FULLTEXT(name), -- 为name字段创建全文索引以便快速搜索特定成员
FOREIGN KEY (created_by_uid) REFERENCES users(id),
FOREIGN KEY (father_id) REFERENCES family_members(id),
FOREIGN KEY (mother_id) REFERENCES family_members(id)
);四、固定长度编码是什么?
为了让查询更加准确,我们使用了一种叫做“固定长度编码”的方法。每个家族成员的ID都被转换成四位数字,并且每级之间用“-”连接。例如,如果一个人的父亲ID是1,那么在他的index_id中就会显示为”0001″。这样做可以确保我们在查询时不会把“11”误认为是“1”。
五、如何插入数据?
当你添加一个新的家族成员时,需要根据他/她的父亲或母亲的index_id生成新的index_id。比如,如果你要添加一个人的儿子,你就要把他父亲的index_id加上儿子自己的ID(同样转成四位数),然后中间加个“-”。这样就形成了儿子完整的index_id。
六、查询示例
假设你想找到所有直接或间接的父亲ID为“0001”的成员,你可以这样查询:
SELECT * FROM family_members WHERE index_id LIKE '0001-%';这会返回所有以“0001-”开头的记录,也就是所有“0001”这个人及其配偶的所有后代。
如果你想快速找到名叫“张三”的成员,可以利用全文索引进行搜索:
SELECT * FROM family_members WHERE MATCH(name) AGAINST('张三' IN NATURAL LANGUAGE MODE);七、断代问题
在族谱数据库设计中,处理断代问题确实是一个挑战,尤其是在需要插入新数据时可能会导致index_id的大范围更新。为了解决这个问题,同时保持高效的数据管理和查询能力,我们可以考虑以下几种策略:
1. 使用基于节点的路径编码(Materialized Path with Node-Based Approach)
这种方法通过引入额外的信息来最小化对index_id的影响。具体来说,可以将每个节点的位置信息存储为一个包含其所有祖先节点ID的列表。这样,在插入新的节点时,只需要更新受影响的直接子树部分。
例如,对于一个节点0001-0002-0003,如果需要在其下插入一个新的节点,只需修改这个特定分支的index_id,而不需要更改整个树结构中的其他节点。
示例:
-- 插入新节点到"0001-0002"之后
UPDATE family_members SET index_id = REPLACE(index_id, '0001-0002', '0001-0002-0004') WHERE index_id LIKE '0001-0002-%';2. 利用关系型数据库特性
MySQL提供了多种索引和搜索优化技术,可以利用这些特性来间接解决问题。例如,可以通过增加辅助表或字段来追踪层级关系,而不是完全依赖于index_id。这种方法虽然增加了复杂性,但在处理动态插入时更加灵活。
3. 使用NoSQL数据库或其他替代方案
对于非常庞大或频繁变动的数据集,传统的SQL数据库可能不是最佳选择。NoSQL数据库如MongoDB等,提供更灵活的数据模型,适合存储层次结构,并且在处理断代问题上具有天然优势。
结合实际应用选择最适合的方法
没有一种方法能够完美适用于所有情况,选择哪种策略应基于具体的业务需求、预期的数据规模以及维护成本等因素综合考量。而对于那些需要处理更大规模数据或更为复杂的场景,则可能需要探索第二种甚至第三种解决方案。
无论采取何种策略,关键是确保所选方案既能满足当前需求,也能适应未来的变化和发展。
八、总结
通过这种方式,即使是没有太多技术背景的人也能轻松地管理和查询家族历史。无论是记录新成员的信息,还是寻找某个祖先的所有后代,都变得简单明了。希望这篇文章能帮助你开始自己的家族历史之旅,让珍贵的记忆得以传承。